



Longhorn is great. I love their backup, snapshotting, and expand features. One constant annoyance that I continue to encounter in the wild is HOW DO YOU MOVE A VOLUME!
There is no “move volume from this node to this node” button. I feel as though this needs to be a feature.
I get it, usually when a customer is using Longhorn, they are opting to use the default number of replicas which is 3. In this case, you don’t need to move volumes.
In scenarios where volumes can become very large (think TBs) you quickly run into deployments with only one replica. At my current job, I have Longhorn volumes as large as 16TB. Obviously, you can’t justify multiplying that by 3 and taking up that much storage.
So, what happens when a node becomes full, and the storage is all used up? You can’t expand disks, you can’t take snapshots, and you don’t have an ideal situation. From what I can glean from the current Longhorn docs, there are really only two paths forward.
The first is almost exclusively a Harvester use case. Harvester VMs run on nodes; the volumes attached to those VMs may not necessarily run on the same node. Let’s take my homelab as an example.

I have a few VMs running here. You can see that some are running on harvester1 and some are running on harvester2. Let’s take a look at Longhorn…

You can see that storage is not evenly distributed across both nodes. There isn’t really any reason for this. I don’t have any rule that says try and schedule across nodes evenly. But let’s say that I want to move a volume from harvester2 to harvester1…

The kube-node-03 machine is running on harvester2 and has the volume scheduled to harvester2. I want to move that volume to harvester1. A simple way to do that is to utilize the data locality feature of longhorn.
In Harvester I am going to schedule this node to harvester1.
I can do this by live migrating it or by powering the VM down and scheduling it explicitly. Let’s do the second option.

VM is powered off, we are scheduling it to harvester1, and we are turning it back on.

Back in Longhorn, we update the “Data Locality” to “best-effort”.

A new volume spawns on harvester1

The state goes to “Rebuilding” as the new volume is getting replicated on the harvester1 node.

Badda-bing-badda-boom. The volume is now on harvester1.
We can update the data locality again to the default value and if we want, we can reschedule the VM itself back to harvester1.
This method requires downtime of course but the nice thing is that Longhorn takes care of removing the old volume on the other node for you.
The second method is simple as well. In this scenario, we update the replica count. The only difference here is that Harvester and Longhorn will decide which node to schedule it to (I only have two nodes, so it is easy).
We will be working on the same volume.

Let’s update the replica count to 2.

Longhorn is now complaining that the volume is degraded because it sees we want 2 replicas but only have 1.

The replica gets rebuilt on harvester2.
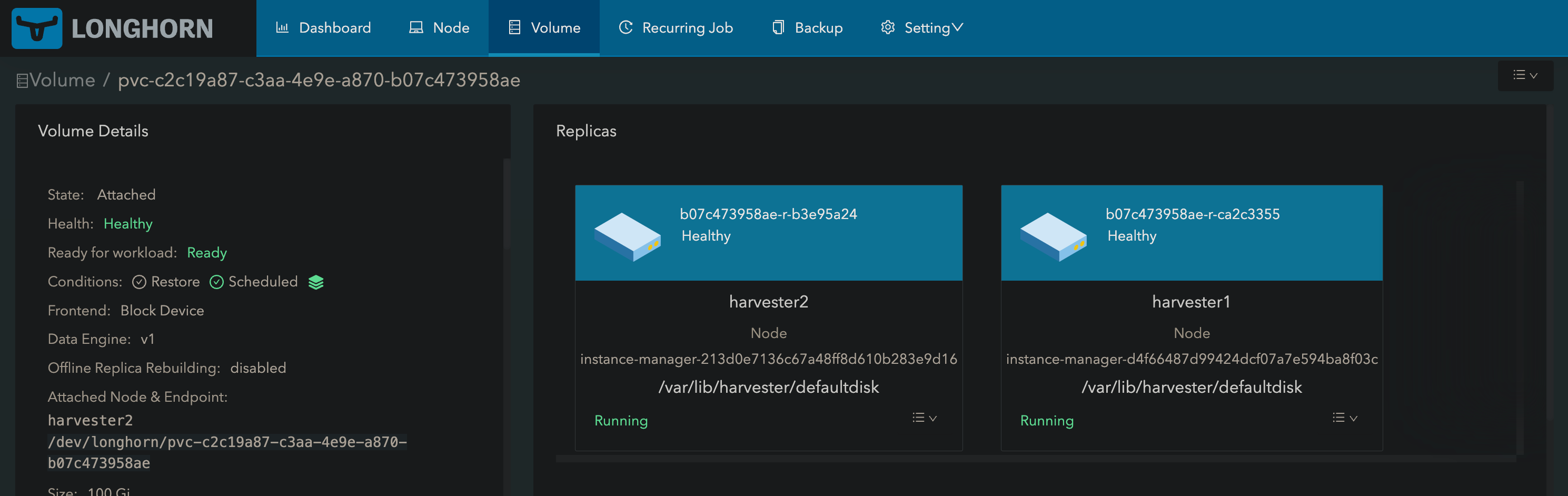
We now have two replicas.

Now we update the replica count again to 1.

And we delete the one scheduled to harvester1.
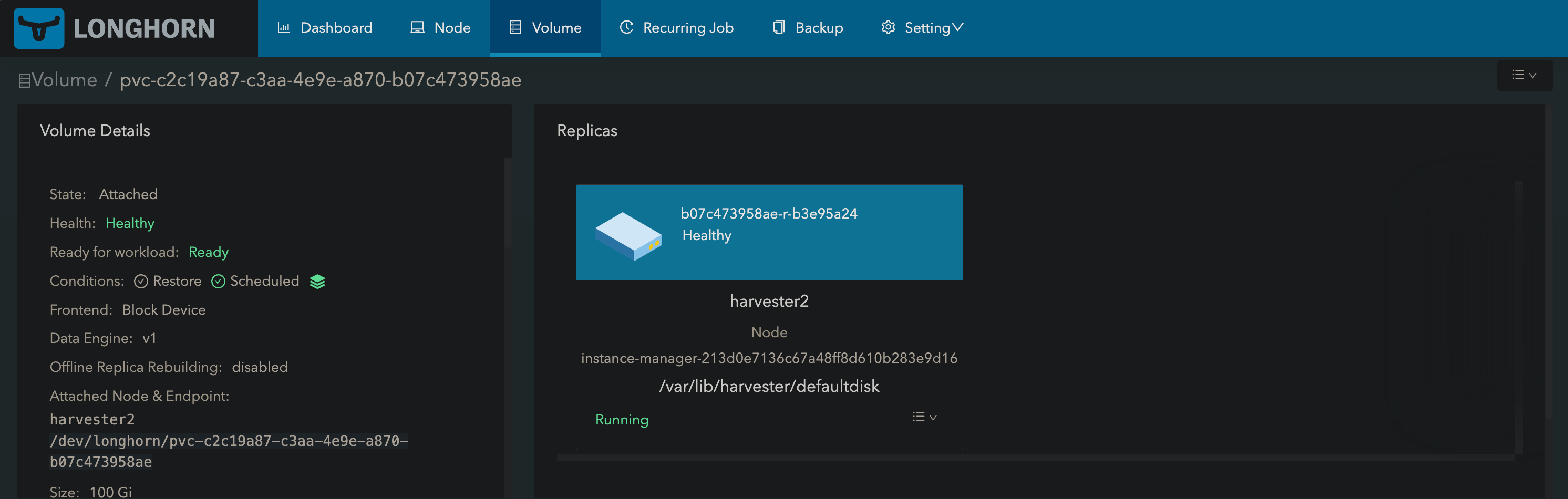
And we are back on harvester2.
The second option is good if you don’t really care where the replica lands. The first option is good if you want to schedule the new replica to a specific node.
Anyway, I hope this was helpful.
Cheers,
Joe