



Removing a Harvester Node the Right Way
Using Longhorn


If I had a dollar for every time I deleted a Harvester node only to realize that my VMs on that node were in a failed, unrecoverable state, I would be rich.
Now, to be fair, home labs are meant to be broken. I am constantly performing clean installs of Proxmox, Harvester, TrueNAS Scale, etc. In my home lab environment, however, I have not set up Ansible scripts or Terraform scripts to spin my hypervisors back up. I will get around to writing those scripts eventually, it just seems overkill at the moment.
So what do I mean when I say “delete a Harvester node”?
A Harvester setup can have two configurations. The first configuration is a single node. The second configuration is a cluster of nodes. In order to have a fully HA (highly available) Harvester cluster, you need more than one node.
Over the last few months, I have had a two node Harvester cluster. I have two Hyve Zeus servers and they are phenomenal. Recently, I decided to install Proxmox on one of them and virtualize a Harvester node on top of that. That was an interesting project.
Obviously, no one in their right mind would run Harvester on top of Proxmox (hypervisor on hypervisor). My reason for trying it out was simply “because I can.”
But now, I want to use my Proxmox server for other things. If I look at my Harvester cluster now, I see that I unwisely created a VM on my virtualized Harvester node.It’s not great. If I want to delete harvester-node0, the Kubernetes worker node that is scheduled to it would end up in a failed state. Normally, this would not be a problem. I have a custom storage class set up in my cluster that only schedules one replica of each volume.


It’s not great. If I want to delete harvester-node0, my kubernetes worker node that is scheduled to it, would be in a failed state. Normally, this would not be a problem. I have a custom storage class set up in my cluster that only schedules one replica of each volume.
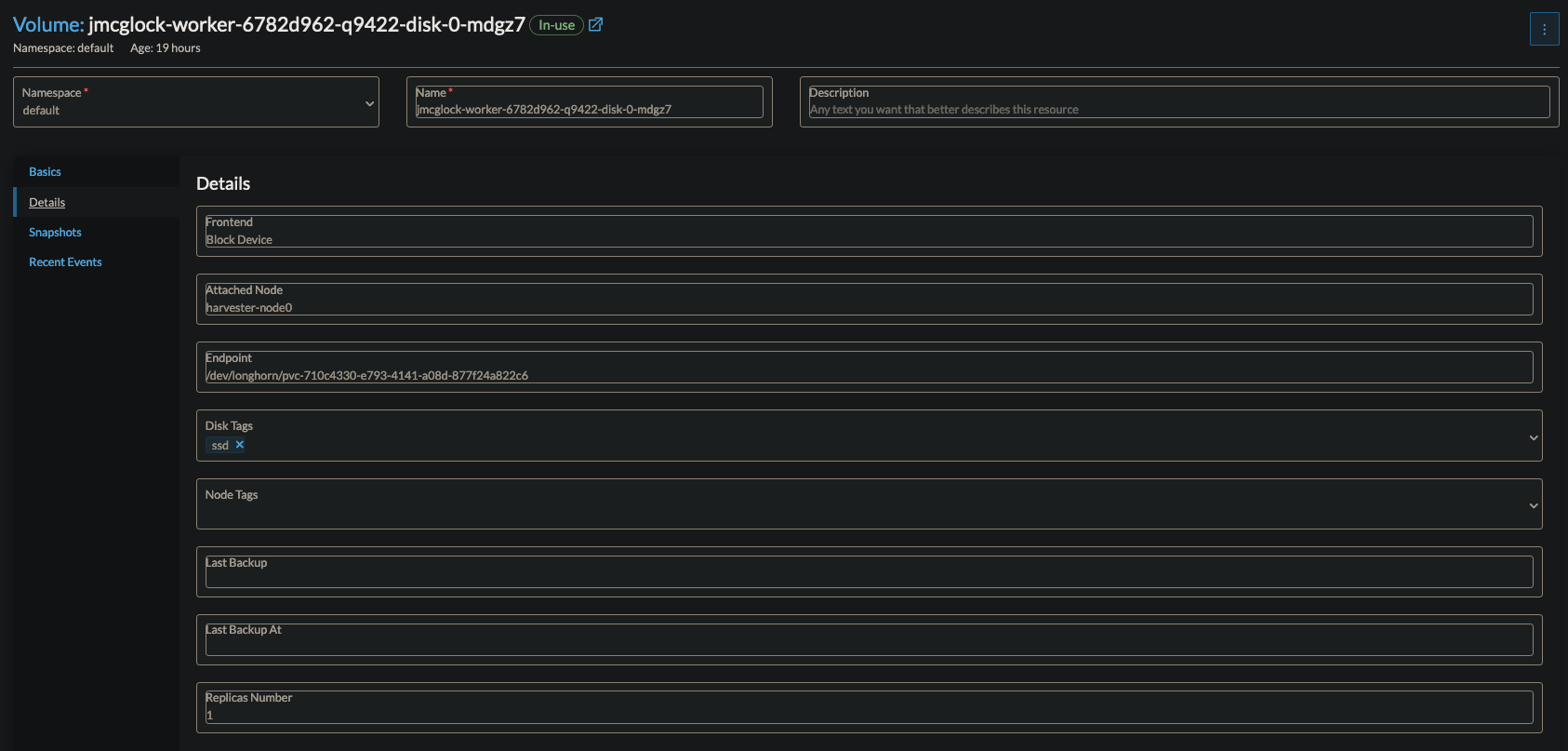
As we can see here, I have one replica scheduled to harvester-node0. You would think that Harvester would have a built-in, automatic rescheduling mechanism that rebuilds the replica on a healthy node. The only problem is, it’s not automatic. Let me explain.

If we look at our hosts again, we can see that there is an option to “Cordon” the node. Cordon marks the node as unschedulable, meaning no new VMs will be scheduled on that node. However, this does NOT rebuild replicas on another node.
In order to safely delete a Harvester node and move VMs that were scheduled to that node to a healthy node, we need to dive deeper and go into the Longhorn dashboard.
First, let's stop the VM (yes my Kubernetes cluster will freak out for a bit but who cares). I would recommend using the graceful shutdown as opposed to the “Force Stop” button.
Now, click on “Support” in the bottom right.

You should see the following.

Click on the little profile icon (here it is the white and red box in the top right) and choose “Preferences”.
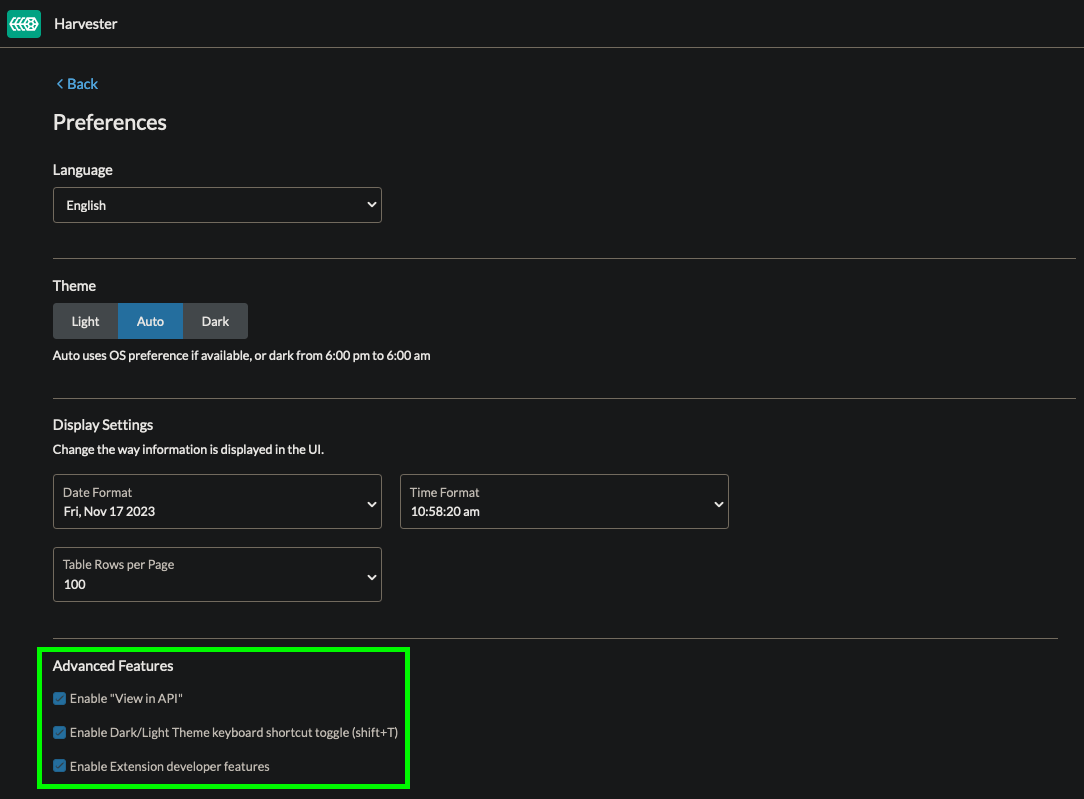
Check each of these boxes and hit the back button. Now we should see the following:

Great! Click “Access Embedded Longhorn UI”. You should see something similar to the following.

Awesome. Let's talk briefly about what's going on here. The 8 volumes are VM boot or data volumes. We can see that we have a combined 939 Gb schedulable across my two nodes.
Notice there are some degraded volumes. These are the Kubernetes monitoring volumes. They want three replicas but I only have two nodes. It's not broken, it's just not optimal.
We can see that there is a detached volume. This is the volume of our stopped VM. Think of VMs as Kubernetes pods that are attached to Longhorn PVCs. When a VM is stopped, the Kubernetes pod is deleted and detached from the PVC. The PVC is retained.
If we click into the detached volume:

Sure enough, this is the volume of our stopped VM.
Disclaimer (this is a little awkward): When I originally went to see where this volume was scheduled, I thought it was scheduled to the harvester-node0 storage pool. However, it turns out it was actually scheduled to the storage pool on the other node. So we wouldn’t really have to worry about this VM going down since the volume was on the node we aren’t deleting.
I still want to show how to migrate a volume off of the node we are going to delete, so I made a second volume on the VM and it got scheduled to the “soon to be deleted node.” All good, the new volume we are looking at looks like this:

You can see this 10 Gb data volume is attached to the harvester-node0 storage pool. In order to migrate it off this node, we need to go to “Node” and go to the dropdown on the right and choose “Edit node and disks”.

Now that we are editing the node, we need to check two boxes. Set “Node Scheduling” to disabled and “Eviction Requested” to true.
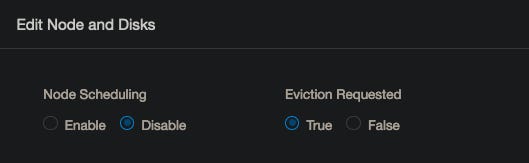
Once we do this, Longhorn will begin rebuilding the data volume on the correct node.
You have to be quick to see it rebuilding. We can check that it was successful by looking at the volume again (notice the name is the same except for the characters after the -r-):
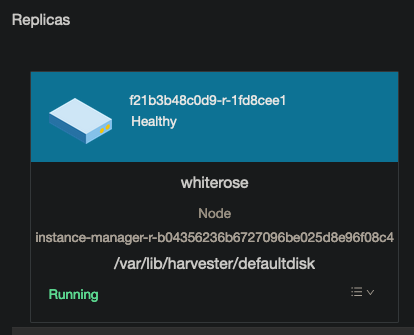
Amazing. Now if we go into nodes, we will see no volumes on the soon to be deleted node:

Awesome. This node can now be deleted.
After you delete the node, you may see the dashboard go down for a few seconds. This is expected behavior.
Since our VM is turned off, once we delete this node, it will get rescheduled to the active node automatically. Let's see it happen!

Very cool. We now see it scheduled to the active node.
TLDR:
Stop any VMs scheduled to the “to be deleted node”
In Longhorn, set "Node Scheduling" to disabled and "Eviction Requested" to true for the node
Watch the volumes get rebuilt on the active node
Check Longhorn to ensure no volumes are still scheduled to the “to be deleted node”
Delete the node and wait for the dashboard to come back up
Start the VMs and watch them get rescheduled to the active node
Cheers,
Joe